If you’ve been reading Byte by Byte for any length of time, then you know that I have one mantra that I repeat over and over again:
Strategy, Strategy, Strategy
This is the one biggest difference between those students who succeed and those who fail at their coding interview. It’s not who has studied the most problems. It’s not who grinds the most Leetcode. It’s not who is naturally the smartest.
The biggest difference is having a strategy for solving ANY problem, not just the ones you’ve seen before. And this approach is why our students see such fantastic results.
But…
Here’s the thing about strategy: Without the proper building blocks in place, you’ll never succeed. That’s why Data Structures are so key.
Trying to nail a coding interview without having your Data Structures down cold is like trying to play basketball without knowing how to dribble. All the strategy in the world won’t help you be successful.
So in this post, I’m going to share with you ALL of the data structures and algorithms that you need to be successful in your coding interviews.
Table of Contents
One last note before we get into all these Data Structures. If you’re new to this stuff, there’s a lot to learn. This post may feel completely overwhelming. But you can do it!
Remember the following:
- Take things one step at a time. Don’t worry about everything you have to learn. Just focus on learning one things first and then move on to the next.
- Apply these strategies for studying effectively
- Focus on consistency. This is a marathon, not a sprint, so just focus on making consistent progress over time.
If you do these things, you’ll get your Data Structures nailed down in no time.
Arrays
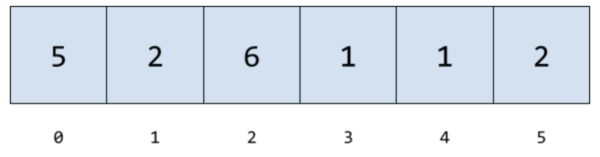
Although arrays are one of the simplest data structures out there, that DOESN’T mean you can skip over them. In fact, quite the opposite.
Because these are so simple and so fundamental to everything that we do in programming, they come up more than anything else. And remember what we said, if you want to be successful, you have to nail down the basics.
What are Arrays?
An array is simply a collection of data that is stored sequentially in memory. This allows us to access our data very efficiently because we know exactly where in memory that data is stored. It also requires very little overhead, making it super space-efficient.
But arrays aren’t without their downsides. Because the memory for the array is allocated in advance, if you want to make the array larger, you need to make a brand new array and copy over all of the data. There is also no way to know the contents of the array or whether it contains certain values without scanning over the entire array.
How are Arrays used in coding interviews?
Arrays are used almost universally in coding and in interviews alike. In many languages, this is the one type of collection that is actually built into the language itself, so as you will see later in this post they are used to build lots of the other data structures that we will use.
Generally, arrays are good to use when your data has the two following properties:
- It is referenced by index
- There is a fixed amount of data
Referencing data by index is key for an array because there is no easy way for us to look up data in our array without scanning over the whole thing. That means that if we need to constantly look up whether a specific value is in our array, we’d be better off using something like a Set or Map.
As we mentioned earlier, resizing arrays is also not a trivial task. Therefore, we want to use them in scenarios where there is a maximum number of items that will be stored in our array. If we want an array that resizes, we’d be better off using some sort of List.
How to recognize when to use an Array
Array problems are generally pretty obvious, as they will explicitly require you to manipulate an array in some way. Unlike other data structures that may be less obvious, arrays should just be used when the data is already in array form or it matches the criteria we listed above.
Common Array algorithms
There are several array algorithms that you should be comfortable implementing for your coding interviews:
- Using Multi-Dimensional Arrays
Multi-dimensional arrays are a common way to add complexity to array problems in an interview. It’s critical that you be comfortable applying all the common array operations in multiple dimensions - Using Multiple Pointers
While not exactly a singular algorithm, traversing an array with multiple pointers simultaneously is a very important technique - Sliding Windows
This is a super useful technique used for finding subarrays that match specific criteria. It also demonstrates a lot of other relevant techniques such as using multiple pointers in an array - Sorting and Searching
Arrays are a common format for data that we want to sort and search. Knowing how to do binary search as well as sort using common algorithms like Mergesort and Quicksort is a must
With these basic algorithms under your belt, you’ll be able to manipulate arrays in all sorts of different ways.
Practice Array coding interview questions
Here are some common array coding interview questions. I highly recommend practicing these as you would solve problems in an actual interview.
Strings
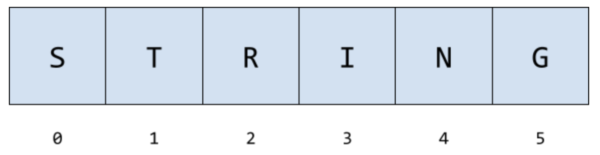
Along with arrays, Strings are one of the simplest data structures out there that comes up all the time. In fact, Strings are really just a subset of arrays: They are arrays of characters. So now that we’ve already covered arrays, Strings will be a lot easier.
What are Strings?
As mentioned, Strings are simply arrays of characters. However, just because they’re simple doesn’t mean that they don’t come with their same intricacies and challenges.
There are two important properties that we need to remember as we start working with Strings:
- In most languages, Strings are immutable
This is a big difference between Strings and arrays, because if you want to change a single character in a String, it’s not so simple. We can’t just say “change character at index 10 to ‘a’” without having to make a copy of the entire string.
This is super important for us to keep in mind because in cases where we want to be able to modify our string, we’ll want to use something like an array of characters or a class like Java’s StringBuilder. - Like arrays, Strings are variable in size
This one might be obvious, but it bears repeating. In most languages, arrays are treated as a collection, whereas we think of a string as a single “thing”. However, remember that it’s still an array of characters on the backend, so the space the string takes up AND the amount of time it takes to do things like generate a hash of a string are proportional to the length of the string.
How are Strings used in coding interviews?
Unlike arrays, Strings really only have one use, which is very self-explanatory: Doing stuff that requires strings.
For example if your input is a string, then you know that you’ll either need to use the string as is or parse it in some way. If you’re outputting text, then you need to generate a string.
Because Strings are fairly tightly defined in their purpose, it’s unlikely that you’ll end up using Strings in some broader capacity, since you would basically always use a more suited data structure like an array.
How to recognize when to use a String
Look for problems that take a String as input or produce a String as an output.
Common String algorithms
I’ve already discussed Strings at length in this post, so I won’t go into a ton of detail here. However, to reiterate, these are the String algorithms that you need to know:
- Using 2 Pointers
Same as with arrays, it is common to use multiple pointers to traverse a String. This allows us to accomplish various interesting tasks with substrings and comparing characters - String Math
One of the more annoying things we can have to do, that nevertheless comes up fairly often, is various forms of string math. This includes converting characters to their index in the alphabet, converting characters to their numeric value, converting Strings from String to integer, and more. General familiarity with how to do these things is critical - String Sliding Windows
Again, similar to arrays, sliding windows are common with Strings. They are a great tool for finding the longest substring matching X property - String Comparison, Alignment, and Matching
One of the common things we might want to do with strings is to compare them in some way. For example, do two Strings match? What is the best way to align two Strings to minimize the difference between them. - Regular Expressions
Now you DEFINITELY don’t need to become an expert on regular expressions for your interviews, but at least understanding the basics of wildcard matching and how to construct simple regexes will be very helpful. It is also good to understand how to use regular expressions in your language of choice. - Named String Algorithms
I don’t recommend spending a lot of time on these, but if you really want to go deep on Strings, KMP, Boyer Moore, and Rabin-Karp are good algorithms to explore further.
Practice String coding interview questions
Here are some common String coding interview questions. I highly recommend practicing these as you would solve problems in an actual interview.
Linked Lists
Linked Lists are a really useful data structure that come up frequently in coding interviews. Not only are they structurally very simple, but they resolve one of the biggest issues with arrays that we talked about earlier: They are not fixed in size.
Linked Lists accomplish this by making a tradeoff between accessibility of the data and space usage. Unlike arrays, linked lists can only be accessed in order. That makes them a great tool when we only need to access the most recent data or we have to iterate over our data anyway.
What are Linked Lists?
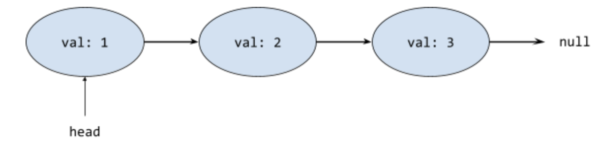
A linked list is simply a list of nodes that store data and are connected together by pointers.
Here’s a very simple example of what our Linked List might look like:
|
1 2 3 4 |
class ListNode { ListNode next; int val; } |
In this example, we have our head node, which we are using as a reference to our list. Then we are able to access the further nodes in the list by traversing to the each next node.
There are also several other variations of linked lists that we can have. For example, we could also include a pointer to the previous node, giving us a doubly linked list:
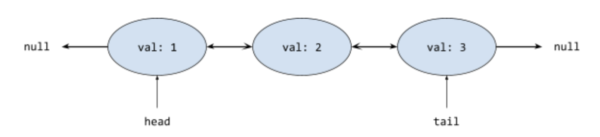
|
1 2 3 4 5 |
class ListNode { ListNode next; ListNode prev; int val; } |
Depending on how we want to use our linked list, we may choose to use one or the other. Singly linked lists are more limited, but they have the advantage of being simpler to implement and work with, whereas doubly linked lists give us more flexible access to our data.
How are Linked Lists used in coding interviews?
While there are plenty of coding interview questions that will ask you to work with linked lists explicitly, there are also lots of times in interviews where you will use them implicitly.
Any time you want to store data using a list, you have the option to use a linked list for that purpose. However, most of the time, you won’t be explicitly implementing it. It is critical that you are familiar with the standard list implementations for your language of choice.
When you ARE asked to explicitly implement a linked list, it is often in problems reliant on your understanding of how the data structure itself functions. For that reason, it is extremely useful to understand deeply the data structure itself and how to manipulate it effectively.
How to recognize when to use a Linked List
Linked list problems are often explicitly defined as such. You’ll see problems that tell you to either take in a List Node as input or given a full list to deal with.
The key with linked lists is that you only need to implement it yourself if there is an explicit reason to. If you just want to use a list to store data, go with a builtin list type. However if you want to be able to manipulate the individual nodes and work with them, then implementing your own list can be useful.
Common Linked List algorithms
When thinking about more complex data structures like lists, the best starting point is to consider what kinds of manipulations you might want to do to that data structure? Given the data, what might I want to do with it?
You’ll see that here with our linked list algorithms:
- Insert a node into a linked list
The most basic operation that we have with any data structure is to add data to it. Try adding a node to different positions within the linked list. How does it differ if we’re adding a node to the beginning versus the end? How does it differ for a singly vs doubly linked list? - Remove a node from a linked list
Along with adding nodes to our list, we need to be able to remove nodes from our list. If we combine adding nodes and removing nodes, we could do something slightly more interesting, like swap two nodes in the list. - Iterate over a linked list
With data in our data structure, we need to be able to access the data. With linked lists, there’s really only one way to do that, which is iterating over the list. - Iterate over a linked list with multiple pointers
Just like we’ve already discussed, using multiple pointers allows us to do various comparisons and count items in ways that we can’t otherwise. Getting comfortable with this process of manipulating multiple pointers at the same time will prove very useful. - Reverse a linked list
While this is not strictly necessary, it is a good technique to understand because it contains a lot of sub-strategies for manipulating linked lists that you will find useful. I recommend getting a firm handle on this.
Practice Linked List coding interview questions
Here are some common linked list coding interview questions. I highly recommend practicing these as you would solve problems in an actual interview.
- Find the Nth-to-Last Element in a Linked List
- Linked List Palindromes
- Print a Linked List in Reverse
- Split a Linked List
- Dedup a Linked List
- Tree to Doubly Linked List

Sets
Sets are probably the biggest workhorse of coding interviews. Sets allow us optimize all sorts of coding interview problems that we would be unable to speed up without. However, since we don’t often see “set interview questions,” they tend to get overlooked.
What are Sets?
Sets are another collection data structure, but unlike all the other data structures that we’ve looked at, they have three unique properties that make them particularly useful.
- Sets cannot contain duplicates
- Sets are generally optimized for testing membership
- Sets are unordered
The first property, not containing duplicates, makes sets really useful for doing things like deduplicating our data. Deduplicating data is as easy as adding it to a set because the set will deduplicate the data for us.
That along with the second property make sets a great tool for checking whether values are contained within our data. Like with deduplicating, it’s easy to add all of our data to a set and then check any new data to see if it’s already in the set.
Since sets are optimized for checking membership, that allows us to do these sorts of tests much more easily than with something like an array. Set implementations can generally look up whether a value is in the set in O(1) time, allowing us to quickly and easily check for membership.
Finally, the third property is not necessarily going to help us, but it is something that we need to remember. If we add data to a set, we are giving up ordering of that data in exchange for easy membership checks. In most cases, we won’t be able to recover the data in the original order, so that’s something that we need to keep in mind.
How are Sets used in coding interviews?
As I mentioned, sets are a fantastic tool to use in coding interviews for optimization purposes. Generally, look for places that you are checking for membership in a collection of data.
For example, if you find yourself repeatedly iterating over an array to check whether or not it contains a specific value, that could easily be optimized by adding all the data to a set. Rather than iterating over the array, which takes O(n) time for every check, adding it to a set would take up extra space but allow us to perform each check in O(1) time.
Sets are also great for removing duplicate data as I mentioned earlier.
How to recognize when to use a Set
I have yet to see more than one or two coding interview questions that were explicitly “set interview questions.” However, that doesn’t mean that you won’t find yourself using them in your interviews.
Look for opportunities to optimize problems by getting rid of any costly membership tests. Rather than iterating over other data structures, consider adding all of your data to a set to test membership.
Common Set algorithms
It’s unlikely in an interview that you would implement a set directly. Much more likely you would use the tools built into your language of choice. However it’s still good to be familiar with common operations, and implementing a set along with these algorithms is a fantastic exercise for improving your overall understanding.
- Add a value to the set
Since sets are often not fixed-size data structures, it is useful to consider different ways in which the underlying data storage can resize to fit the needs of the current data. - Does set contain a value?
This is the bread and butter of a set. Ideally with most sets, we want to be able to do this in constant time, likely through some form of hashing. - Remove a value from the set
If we want to remove data from the set, how do we do that efficiently? - Find the union or intersection of two sets
With multiple sets, we may want to look at the overlap in the data. These are a higher order algorithm relative to setting and getting values, but it is very useful and helpful to implement if you want to improve your understanding of how the underlying set works.
Practice Set coding interview questions
Here are some common set coding interview questions. I highly recommend practicing these as you would solve problems in an actual interview.
Maps
Image from xnorcode.com
Along with Sets, maps are the other behind-the-scenes data structure that is incredibly useful during coding interviews. Like sets, they allow us to store and access values very quickly, but unlike sets, they are more generalizable since they work using key-value pairs.
What are Maps?
Maps are simply data structures that store key-value pairs. The key and value can be any sort of data, allowing us to easily store and access whatever data we’d like.
What makes maps incredibly useful is two main characteristics:
O(1)lookups- Data association
The O(1) lookups are useful for the exact same reason why they are useful with sets: They help us find the data that we need much more quickly.
It’s important to be aware that in many implementations, this O(1) lookup is more of an average-case than a worst case, but it is still very fast for most of what we want to do.
Data association is also a really useful component. Whenever we have pairs of data that are related or want to be able to use one piece of data to reference another, this is incredibly useful.
The simple example that we’re all already familiar of key-value pairs is array indices to values. The array index is a key, and the data in the array is the value.
Maps simply allow us to generalize this association so that we could, for example, map customer names to customer data or dates to data logs.
How are Maps used in coding interviews?
Similar to sets, maps are primarily used in coding interviews for optimization purposes. Rather than being asked as standalone data structures, they allow us to get rid of slow lookups in our code.
Because they provide an actual mapping between data, maps can also be super useful for associating various input or computed data for easy access.
A great example of this is using an LRU (least recently used) cache. In an LRU cache, we want to store our data in some sort of ordered list so that we know what the oldest elements are in our cache. However we also want to be able to quickly access elements in our cache to update them.
Combining a map with a linked list is a great strategy for this because it allows us to quickly look up where values are in our linked list and update them accordingly.
How to recognize when to use a Map
While you’re not likely to get “map interview problems,” again maps are incredibly useful behind the scenes. Look for problems where you have associated data or you want to be able to easily look up data without doing a linear search.
Common Map algorithms
Like most of our other data structures, the main operations that we will want to perform on a map are manipulation of the data itself. This is a great data structure to implement as a practice exercise, although you are unlikely to implement a map in your actual interview.
- Insert a key-value pair
There is a bit of added complexity here compared to a set, because we have to check whether our key already exists. If so, what do we do with our data? It is useful to consider what the different options are. - Remove a key-value pair
If we’re adding data, we definitely want to be able to remove data as well. - Check if map contains a key
Like with a set, we may want to look up whether a value is present. Ideally we’d like to be able to do this in constant time. We may also want to iterate over all the keys in a map. - Merge two maps
This is probably not something that you’re going to do often, but again it’s a good exercise to help reinforce your understanding of maps and I highly recommend working through it.
Practice Map coding interview questions
Here are some common map coding interview questions. I highly recommend practicing these as you would solve problems in an actual interview.
Stacks and Queues
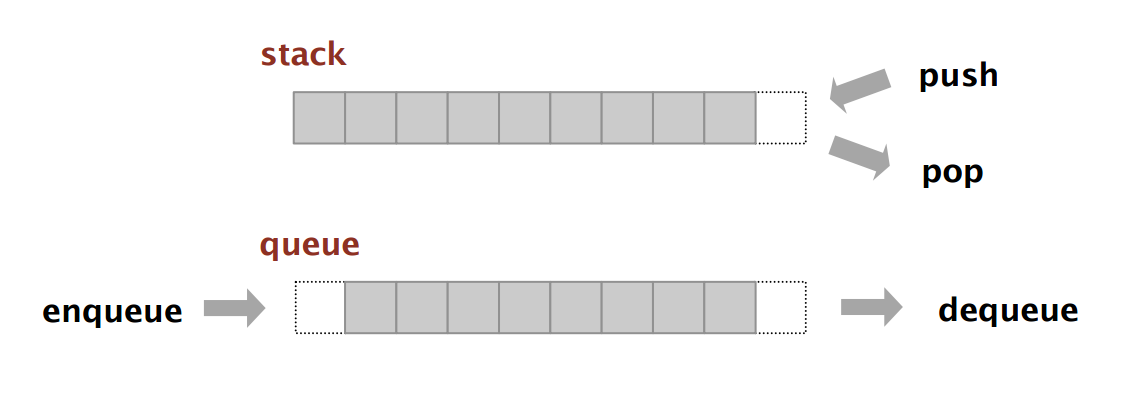
Stacks and queues are really abstract data types, not actually data structures per se. That’s because they define the way in which we interact with our data rather than the structure of the data itself. As we will see, the easiest way to implement these will generally be with a simple linked list.
However, they are very relevant to our interview prep because they allow us to manipulate our data in different and useful ways.
What are Stacks and Queues?
Stacks and queues both define the way in which we interface with our data and the time complexities associated with that.
A stack interface provides LIFO, or last-in-first-out, access to our data. That means that we essentially have 2 main operations push() and pop() which add values to the top of the stack and remove the most recently added values respectively.
Here is a simple example of the results of adding and removing data from a stack:
|
1 2 3 4 5 6 7 8 9 10 11 |
stack.push(1) stack.push(2) stack.pop() => 2 stack.push(3) stack.pop() => 3 stack.pop() => 1 |
Queues, by contrast, provide FIFO, or first-in-first-out, access to our data. Our two operations are enqueue() and dequeue() which add values to the beginning of our queue and remove values from the end of the queue respectively.
Here’s a simple example of the results of adding and removing data from a queue. Note the differences between this and the stack, despite adding our data in the same order:
|
1 2 3 4 5 6 7 8 9 10 11 |
queue.enqueue(1) queue.enqueue(2) queue.dequeue() => 1 queue.enqueue(3) queue.dequeue() => 2 queue.dequeue() => 3 |
Stacks and queues both allow adding and removing data using this core interface in constant time and are easy to implement using a linked list. Depending on how we are using the data, we may favor one over the other based on the order of access that we need.
NOTE: Priority Queues are a completely different thing from what we’re discussing here. A priority queue is a completely different abstract type, commonly implemented using a heap, which we discuss below.
How are Stacks and Queues used in coding interviews?
Stacks and queues are used in a variety of ways in coding interviews as well as featuring prominently in many common algorithms.
Generally speaking, these are good options when we only need to access our data in order. Unlike arrays or linked lists, these interfaces are much simpler, so they are great for applications that don’t require us to do anything more complicated with our data.
A great example of this is BFS (breadth-first search). When doing BFS, we want to maintain a list of all the nodes that we need to visit and do so in order. Therefore, a queue provides us with a very easy way to do this. Could we keep track in a more manual way with a list or array? Sure, but it would be totally unnecessary and make our lives harder.
Generally when considering stacks versus queues, the main question is simply, “What order do I need to access my data in?” If you want to process the data in the order that it was received, then a queue is the way to go, whereas if you want to access the data in reverse order, a stack is best.
How to recognize when to use a Stack or Queue
You very well might see problems that explicitly ask you to use a stack or queue during your interviews. There are some variations on these data structures that can make for interesting interview questions.
In addition, they’re also useful in a variety of problems that aren’t explicit stack or queue problems.
Stacks are useful in two specific cases:
- You want to access the data in reverse order
- You are trying to convert a recursive function to an iterative function
Accessing the data in reverse is common in lots of problems. Maybe you want to see if a string is a palindrome. Maybe you want to see if it has matching parentheses. Maybe you want to implement a calculator and track order of operations. All of these are things that can be relatively easily done with a stack.
You may also notice that all of the above could be pretty easily solved recursively. I find it can be helpful to think about stacks as an explicit representation of a recursive stack. Rather than doing this implicitly using recursion, we’re just doing it explicitly instead.
With queues, the single most common use case is in BFS. They’re useful to have as a tool if you end up in a situation where you want to track the data in order, but BFS is definitely the main use case that you’ll see.
Common Stack and Queue algorithms
For both stacks and queues, the key algorithms are adding and removing data. Because these are usually built on top of linked lists, we want to be able to implement the appropriate interface for each type.
push()
Add a new value to the top of a stack.pop()
Remove the top value from a stack.enqueue()
Add a new value to the beginning of a queue.dequeue()
Remove the oldest value from the end of a queue
Practice Stack and Queue coding interview questions
Here are some common stack and queue coding interview questions. I highly recommend practicing these as you would solve problems in an actual interview.
Trees
Trees are definitely one of the most common data structures that you’ll see come up in interviews. Whether they’re binary search trees, unordered binary trees, n-ary trees, or tries, it’s really valuable to understand how to work with trees effectively.
What are Trees?
In their most general sense, trees are simply directed acyclic graphs (DAGs) where each node can only have a single other node pointing to it.
That means that they are just a set of nodes that point to each other with a few restrictions. However there are a couple of more specific structures that we’ll see most often:
- Binary search tress
- Binary trees
- N-ary trees
- Tries
Let’s break down each of these.
Binary search trees, or BSTs, are probably the most common trees that you’ll use during interviews. The two key characteristics are both in the name: Binary and Search.
A BST is a binary tree, meaning that each node has at most 2 children. They can have fewer, but cannot have more than 2 children.
Being a search tree means that in addition to being a binary tree, the nodes are also in order. A tree is a BST if all the nodes to the left of a given node are less than that node and all the nodes to the right of a given node are greater than or equal to that node.
For example, here is a BST:
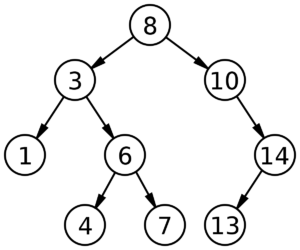
Notice how all the nodes to the left of the 8 are less than 8, whereas all the nodes to the right are greater.
By contrast, the following is not a BST:
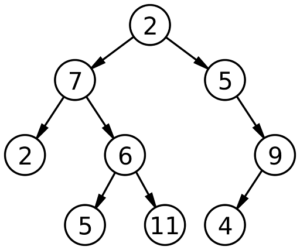
Since the 7 is to the left of the 2, it fails the rules for being a BST.
Binary Trees
Binary trees can be BSTs, but aren’t necessarily. The big difference is that there is no restriction on the order of the nodes in the tree.
The big disadvantage of binary trees over BSTs is that we cannot identify whether a value is in the tree without potentially looking at every node in the tree. Unlike a BST where we know whether a value has to be to the left or right of a given node, a value could be anywhere in a binary tree.
N-ary Trees
N-ary trees are simply the generalized form of a tree. Rather than a binary tree where each node is limited to having at most two children, an n-ary tree can have any number of children.
However, this still requires our graph to be directional and acyclic and for each node to only have one parent.
Here’s an example of what one of these n-ary trees might look like:
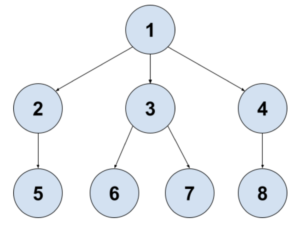
Notice how the 1 node has more than 2 children. N-ary trees allow us to generalize our trees and do things like we’ll see in the next structure.
Tries
Tries are n-ary trees that are specifically used to store string data. Tries are designed to store multiple strings as efficiently as possible by merging the prefixes that are common across multiple strings.
These are becoming more popular in interviews because they do a great job of testing that you understand trees beyond the most basic level.
Here’s an example of what a trie might look like:
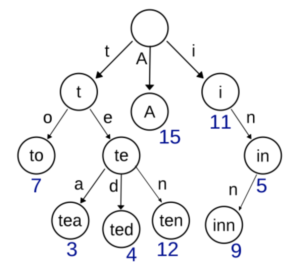
Notice how all strings with the same prefix are merged into the same subtree.
I’m not going to go into a lot of detail on tries here, but I recommend this post for a more in depth discussion.
Note: Many people ask me about things like rebalancing or Red-Black trees. I don’t recommend studying these for your interview. They are so unlikely to come up versus anything else that you can study that the value simply isn’t there.
How are Trees used in coding interviews?
Trees come often in coding interviews because they’re the right amount of difficulty to challenge candidates without taking an unreasonable amount of time for those who understand them.
The most common tree problems that you should expect are ones that involve either manipulation or traversal of trees.
Manipulation can look like building a tree, converting a tree from one format to another, converting a linked list to a tree, inserting/removing nodes from a tree, and the like. These really test that you thoroughly understand how the data is structured.
Tree traversals generally involve iterating over the tree or searching for data in the tree. This is where we will use tools like depth-first search (DFS) and breadth-first search (BFS) to our advantage.
How to recognize when to use a Tree
Most of the time, tree problems will be explicitly stated as such. The problem will come in the form of “Given a tree, do X”.
The most important thing when you see problems like this is to make sure that you understand what type of tree you’re dealing with. If it’s a BST, that has different implications than if it’s just a binary tree that is not sorted.
The two other possible cases where you’ll use trees in problems are:
- Storing data in a BST
- Using a Trie to find string prefixes
Storing data in a BST is something that we may occasionally want to do, although its not usually the most efficient option. If you end up doing this, you’ll probably want to use a built in tree structure rather than implementing your own, since that will provide additional benefits like rebalancing.
If you’re trying to find strings by their prefix, then tries are inherently a great way to do that. For example, if you wanted to implement an autocomplete tool, tries would be a good option.
Common Tree algorithms
Like all other data structures, our basic algorithms involve manipulating the core data itself. However, being slightly more complicated, trees are also a data structure where we want to be sure we know how to access all of our data as well.
- Insert a node
How we insert a node into our tree is going to depend on the details of the specific implementation. If we are inserting into a BST, then there is only one correct place for the node to go. If it’s a binary tree, we put the node in the next open position that’s available. - Remove a node
This can be a little tricky. If the node is a leaf node, we just remove it, but if it has one or two children, what do we do with those? Especially in BSTs where we have to maintain order, it is important to understand how to remove a node. - Depth-first search (Inorder, preorder, and postorder traversals)
DFS is our recursive traversal of the tree and allows us to iterate over all the nodes in several different ways. The simplest version of this would be used just to find whether a node is in a tree or not, but we can also use this to find paths between nodes in our tree or iterate over it in different ways. - Breadth-first search (level-order traversal)
BFS is an iterative option for traversing our tree. BFS iterates over the tree level by level, which can be helpful if we want to access the data in that order.
Practice Tree coding interview questions
Here are some common tree coding interview questions. I highly recommend practicing these as you would solve problems in an actual interview.
- BST Verification
- Balanced Binary Tree
- Inorder Traversal
- Level-order Traversal
- Longest Consecutive Branch
- Autocomplete
Graphs
If you understand how to work with trees, graphs are no more challenging. However, they’re definitely one of the data structures that I see students fear the most going into coding interviews. The good news is that, fundamentally, graphs are pretty straightforward.
What are Graphs?
Like trees, graphs are simply data points that are connected in some way. However, unlike trees, which restrict the ways in which that data can be connected, graphs are more general. Data can be connected in many different ways.
At its core, that’s all that graphs are. They are composed of vertices, which store the data, and edges, which represent the connections between vertices.
We can represent graphs in a couple of different ways depending on what we are trying to do:
- Adjacency list
- Adjacency matrix
Adjacency List
These are probably the most common way to represent a graph. An adjacency list just stores the edges of each node. In that way it allows us to easily find all the nodes that any given node connects to.
For example, here is a simple graph and its associated adjacency list:
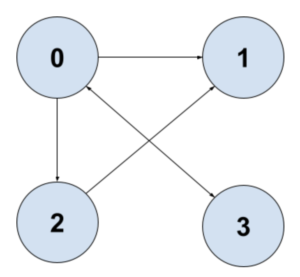
|
1 2 3 4 5 6 |
adjList = { 0: [1,2,3], 1: [], 2: [1], 3: [0] } |
As we can see, this is a very efficient way to store this data in memory and it’s easy for us to find all the neighbors of a given node.
However, there is one big downside to this approach. If we wanted to ask the question “is there an edge from Node A to Node B?”, that would take O(E) time, where E is the number of edges. We might have to iterate over every edge to determine whether the one we’re looking for exists.
In a situation where we needed to look up edges, we might use an Adjacency matrix.
Adjacency Matrix
An adjacency matrix is similar to our adjacency list except that it explicitly defines every possible edge in the graph. Rather than only tracking the edges that do exist, an adjacency matrix is a boolean matrix that contains every possible edge and tells us either True, it exists, or False, it doesn’t.
Take our graph from before and let’s see what the adjacency matrix might look like:.
|
1 2 3 4 5 |
adjMatrix = [[F, T, T, T], [F, F, F, F], [F, T, F, F], [F, F, F, F]] |
With this matrix, if I wanted to figure out whether there’s an edge from 1 to 2, I just look up adjMatrix[1][2].
If we are solving a problem that primarily asks us to do this kind of work, an adjacency matrix is likely better than an adjacency list. However, the big downside is that it uses more space. Our adjacency matrix always takes up O(V2) space, regardless of how many edges there actually are in our graph.
Storing Our Data
Now you may be saying, this is all well and good, but what if I want to store actual data in these nodes rather than just use their indices. Well in this case, the simplest solution is just to add a secondary array or map that maps the node indices to their data.
I highly recommend this approach because, although it may feel like extra work, it is very straightforward, making it harder to mess up.
How are Graphs used in coding interviews?
Graphs are used frequently in coding interviews to compute something that isn’t explicitly about a graph. At the end of the day, graphs are really used for representing relationships between data, so graph algorithms most frequently come up in those contexts.
For example, you might see a problem that asks you to find the path between point A and point B. Or you have to come up with the correct series of moves to solve some sort of game.
Even though they’re not framed as such, these are both graph problems. If you are playing chess, you have the current game state. That then connects to all of the potential next game states after you make a move. Therefore, you have data points that are related to each other. Aka, you can build a graph.
How to recognize when to use a Graph
In coding interviews, there are really two distinct types of graph problems:
- Explicit graph problems
- Implicit graph problems
The explicit graph problems are the ones that specifically ask you to use a graph. They might be something like find the shortest path between two nodes in a graph or manipulate a graph in some way. These ones are pretty straightforward.
However, much more commonly, you’ll see implicit graph problems.
As I mentioned, these are problems that are solved using a graph that is not explicitly defined. There are a couple of keywords that you can look for with these sorts of problems:
- Shortest path to get to X
- Number of edits/transformations/moves to get to X
Essentially you are looking for any data that is implicitly connected. As long as you can say “this is my current states and these are all the other states I can get to from here,” it is a good candidate for a graph problem.
Common Graph algorithms
One of the scary things about graphs is that there are a lot of fancy named algorithms that look really intimidating. The good thing is, though, that you don’t need to study any of those for your interview.
Sure if you have extra time and want to learn how Dijkstra’s algorithm works, be my guest, but the chances of it coming up on your interview are vanishingly small.
Instead, you should focus on these three algorithms and get them really dialed in:
- Depth-first Search
Searching is really the bread and butter of graph problems. Like with trees, you can do both DFS and BFS, with the main difference being the order of traversal. I generally prefer DFS because it is simpler to code, so unless I need to use BFS for a specific reason I default to DFS. - Breadth-first Search
The one reason to use BFS is when you want to find the shortest path. BFS searches in order of distance from the origin, so you know if you’re doing BFS that, when you find a path, it is guaranteed to be the shortest path. - Topological Sort
Topological sort is essentially sorting nodes in the graph in order of nodes that point into it. It is often used when we are asked to prioritize or order tasks with different dependencies. For example, if I needed to build my code and different packages depended on other packages, topological sort allows me to identify what order to build in so that all the dependencies are built before the dependent package.
Practice Graph coding interview questions
Here are some common graph coding interview questions. I highly recommend practicing these as you would solve problems in an actual interview.
Heaps
Heaps are one more workhorse that we often use behind the scenes in our coding interviews. If you need to keep your data ordered while adding or removing values, heaps are a great easy way to do that.
What are Heaps?
Heaps are a specialized form of a tree that maintain our data in sorted order. Specifically, they enforce that every node is greater (or less than in a min-heap) all of the nodes below it.
This is useful because it guarantees for us that the root of our tree is always the largest (or smallest) value, allowing us to quickly retrieve that value.
While heaps are basically trees, we normally implement them on the backend using an array.
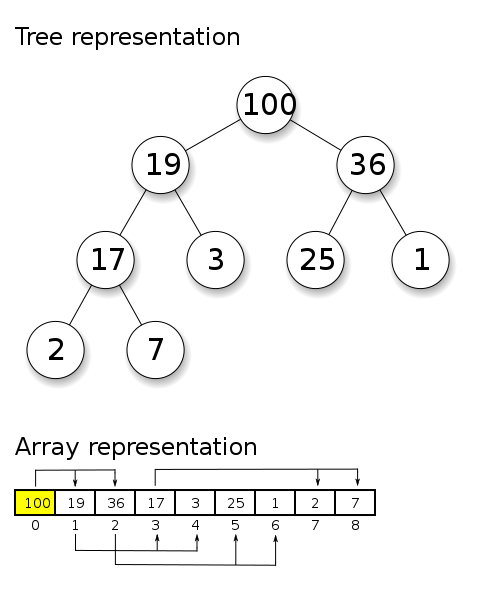
By Kelott – Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=99968794
Here you can see a simple example of how this works. It essentially stores our tree in level order within the array. If I want to access the children of a given node I simply look at index*2+1 and index*2+2.
The main function of our heap is to maintain the invariant above when we add or remove values from it. That means that as we edit the heap, all parent nodes must end up larger than all of their children.
That allows us to do an O(1) lookup of the largest (or smallest) element in our heap at any given time.
Note: While not 100% identical, when you hear people talking about priority queues, those are for all intents and purposes synonymous with heaps
How are Heaps used in coding interviews?
Heaps are really useful if we want to efficiently maintain multiple items in order. Specifically, if we want to be able to regularly reference the largest or smallest item in our collection.
For example, if we’re reading in a stream of values and want to be able to keep track of the max value as we go, a heap could be a good way to do that.
Often times, we won’t be solving “heap coding interview problems” in our interviews but rather using heaps as a tool to solve other types of problems.
How to recognize when to use a Heap
Generally consider using a heap whenever you need to regularly access the largest or smallest value in a collection. Heaps aren’t actually great for accessing sorted data out of order. Unless you want the largest or smallest element, heaps will make it difficult for you.
However if you want to repeatedly access the largest or smallest element, heaps are super useful.
Common Heap algorithms
With heaps, some of the basic operations can be a little tricky to implement so I highly recommend taking the time to practice these.
- Insert
When we insert a new value into our heap, we need to maintain our invariant. We do this by inserting the node at the bottom of our heap and “bubbling up”. - Max
Get the max (or min) value in our heap. This is the bread and butter of our heap data structure. - Remove Max
When we want to remove a value from our heap, we need to do the opposite of inserting a value. To do this, we pull our last leaf node to the top of our tree and “bubble down”.
Practice Heap coding interview questions
Here are some common heap coding interview questions. I highly recommend practicing these as you would solve problems in an actual interview.
Conclusion
At the end of the day, knowing your core data structures is one of the most important things that you can do when preparing for coding interviews. Remember that these are basically the “table stakes”. Without having these dialed in, no amount of strategy will make a difference.
So take your time. Work through these data structures. Really understand them and the algorithms that go with them.
If you found this article helpful, please leave a comment below and let me know what you’re studying next!

